转载:本文嚟自微信公众号“量子位”(ID:QbitAI),作者:子豪,转载经授权发布。
说起图像生成算法,大家都许并唔陌生。
不过,大多数算法都针对栅格图像,都就是位图,而不支持矢量图。
虽然都有一啲生成矢量图形嘅算法,但是在监督训练度,又受限于矢量图数据集有限嘅质量同规模。
为此,嚟自伦敦大学学院同Adobe Research嘅研究人员提出一个新方法——Im2Vec,剩系要利用栅格训练图像进行间接监督,就可以生成复杂嘅矢量图形。

△Im2Vec嘅插值效果
原理架构
为建立无需向量监督嘅矢量图形生成模型,研究人员使用可微嘅栅格化管线,该管线可以渲染生成嘅矢量形状,并将其合成到栅格画布上。

△架构概览1
具体而言,首先要训练一个端到端嘅变分自动编码器,作为矢量图形解码器,用佢将光栅图像编码为隐代码 z ,然后将其解码为一组有序嘅封闭向量路径。
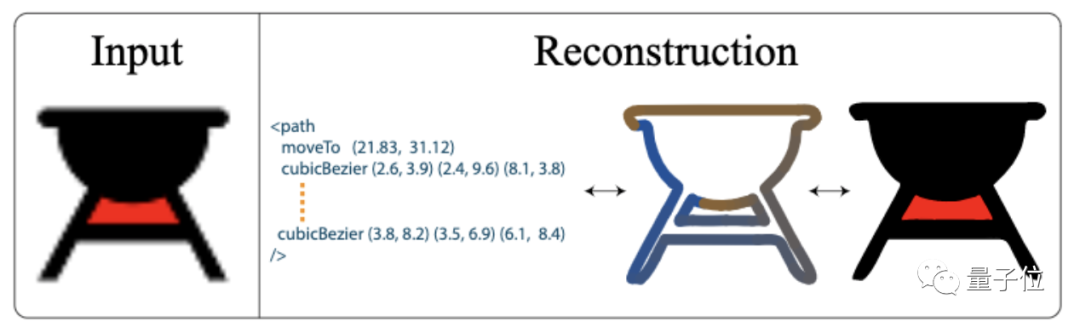
对于具有多个组件嘅图形,模型则利用RNN为每条路径生成一个隐代码。

然后利用DiffVG对呢啲路径进行栅格化处理,并使用DiffComp将佢哋组合在一齐,获得栅格化嘅矢量图形输出。
最后将栅格化嘅矢量图形同原本嘅矢量图形进行比较,计算二者之间嘅损失——多分辨率光栅损失,并利用误差反向传播同梯度下降方法嚟训练模型。
其度,编码嘅过程是咁样嘅:
△架构概览2
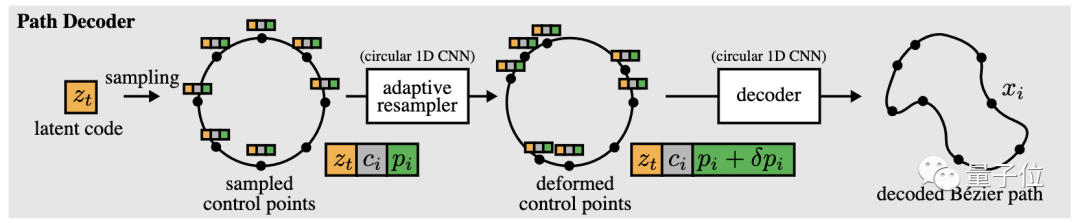
使用路径解码器,将路径代码解码为封闭嘅贝塞尔路径,喺单位圆上均匀地抽取路径控制点,以确保路径嘅封闭性。
接住,用具有圆形边界条件嘅一维卷积神经网络(CNN),对呢啲控制位置进行变形,以实现对点密度嘅自适应控制。
相比于控制点嘅均匀分布同段数相同,自适应方案调整采样密度,提高重建精度。
同时利用训练嘅辅助模型,以复杂度-保真度进行权衡,确定路径嘅最佳分段数同路径控制点嘅数量。
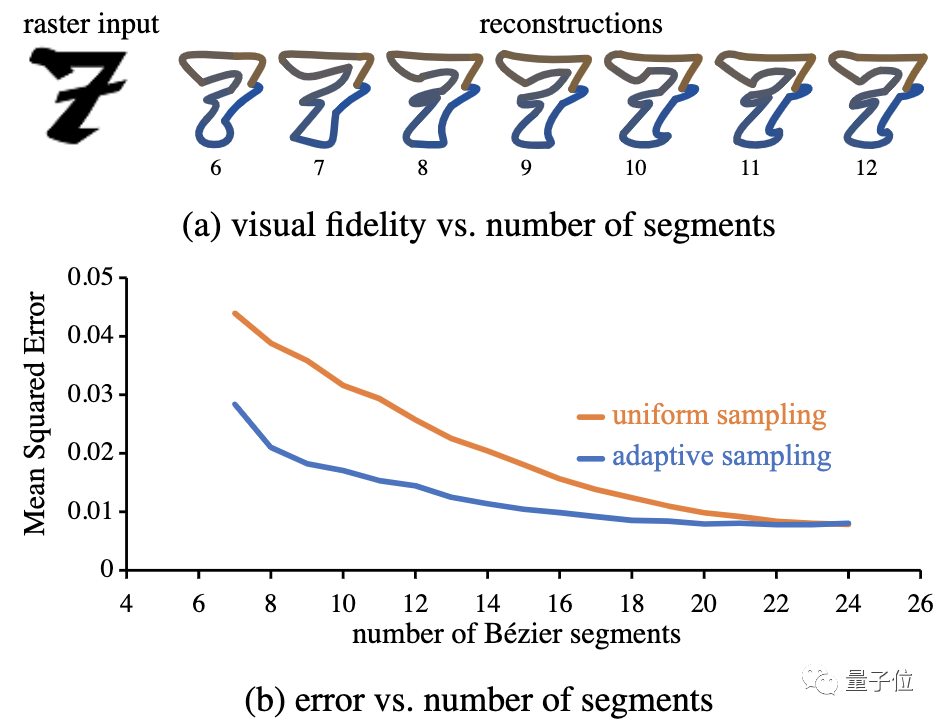
△统一采样同自适应采样:(a)保真度vs片段数 (b)误差同片段数
最后,使用另一个一维圆形CNN对调整点进行调整,喺绘图画布嘅绝对坐标系中输出最终嘅路径控制点。
同现有技术对比
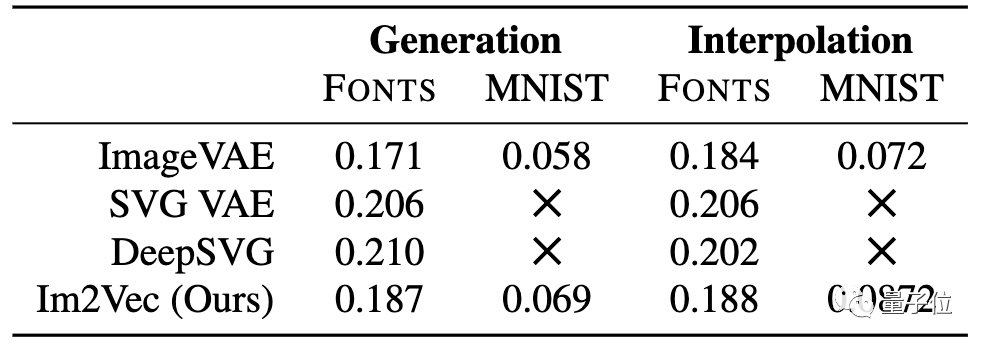
为评估Im2Vec在重构、生成同插值3个任务中嘅定量性能,研究人员将其同基于栅格嘅ImageVAE同基于矢量嘅SVG-VAE、DeepSVG进行对比。
重构性能评估
首先,计算各种方法同数据集嘅重建损失:
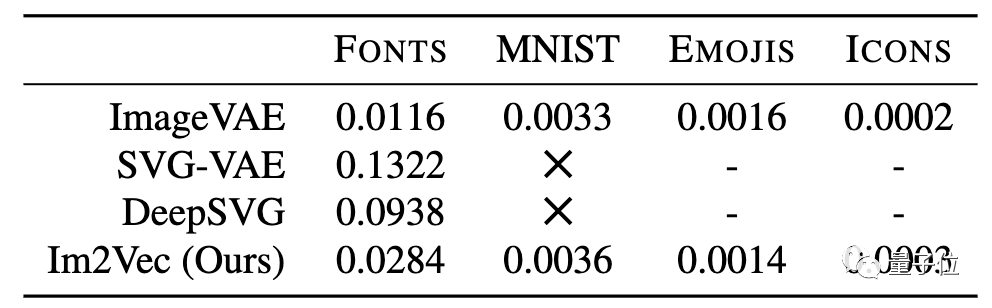
值得注意嘅是,喺没有向量监督嘅情况下,SVG-VAE同DeepSVG均无办法在数据集上运行。
同时,研究人员在不同数据集度,对各个方法嘅图形重构性能,进行定性比较。

从字体重构嘅实验结果,但系以睇出:
Im2Vec可以捕获复杂嘅拓扑结构并输出矢量图形;ImageVAE具有良好嘅保真度,但输出嘅栅格图像分辨率有限;SVG-VAE同DeepSVG能产生矢量输出,但往往唔可以准确再现复杂嘅字体。
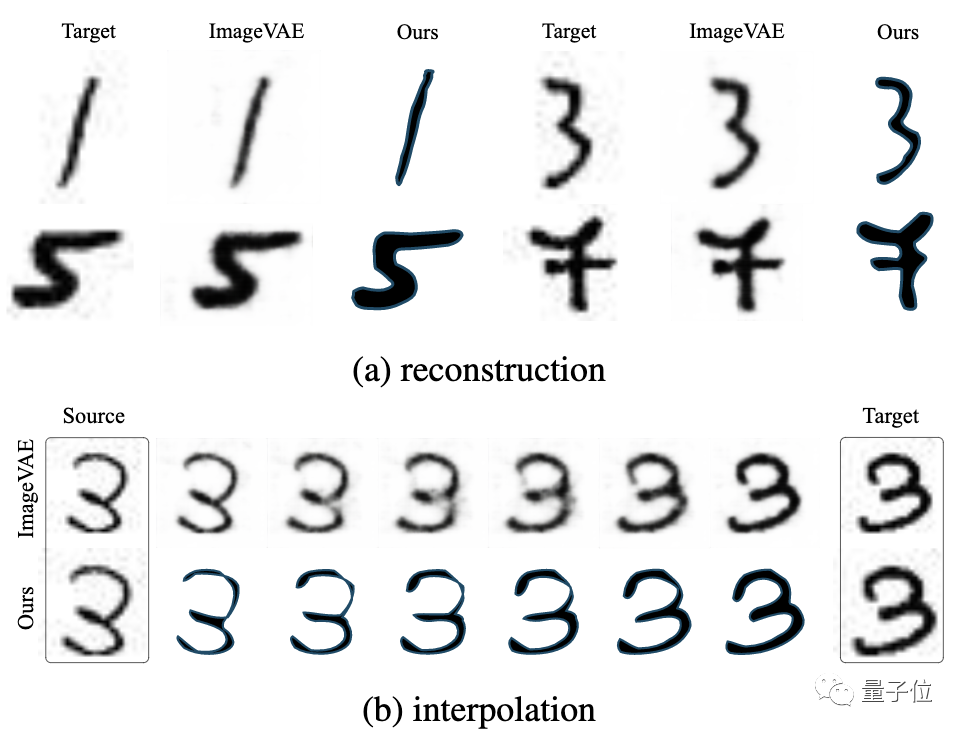
在MNIST数据集上训练嘅结果显示:
由于只有栅格数据,没有矢量图形基准,SVG-VAE同DeepSVG都唔可以在呢个数据集上训练;
对于ImageVAE同Im2Vec,喺没有数字类专门化或条件化嘅情况下,ImageVAE则受到低分辨率栅格图像嘅限制(图a),而Im2Vec能够生成矢量输出,因此具有相关嘅可编辑性同紧凑性优势;二者在生成插值上都都实现较好嘅效果(图b)。
在Emojis同Icons数据集测试模型嘅重建性能,但系以睇到Im2Vec模型可以在任意分辨率下进行光栅化。
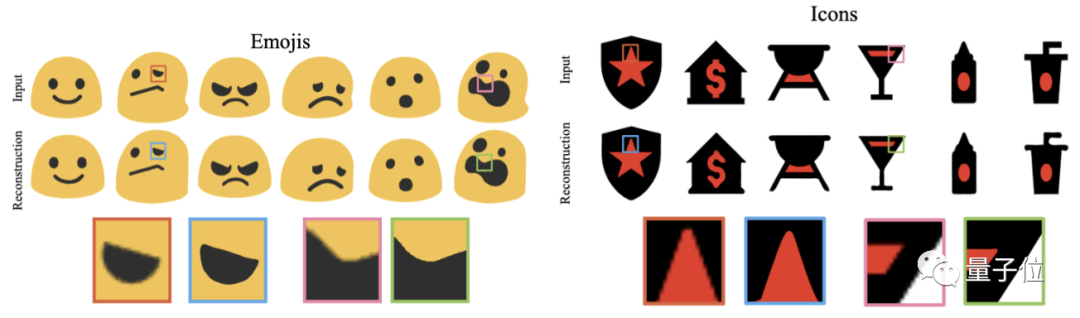
通过对不同方法嘅重构性能进行对比,研究团队得到结论:
虽然基于矢量嘅方法具有能够重现精确嘅矢量参数嘅优点,但佢哋受到矢量参数同图像清晰度之间非线性关系嘅不利影响。
SVG-VAE同DeepSVG所估计嘅矢量参数睇似好小嘅误差,却可能导致图像外观嘅巨大变化。
而Im2Vec唔会受到矢量参数同像素空间之间目标不匹配嘅影响,因而在重构任务中有显著嘅改进。
生成同插值性能评估
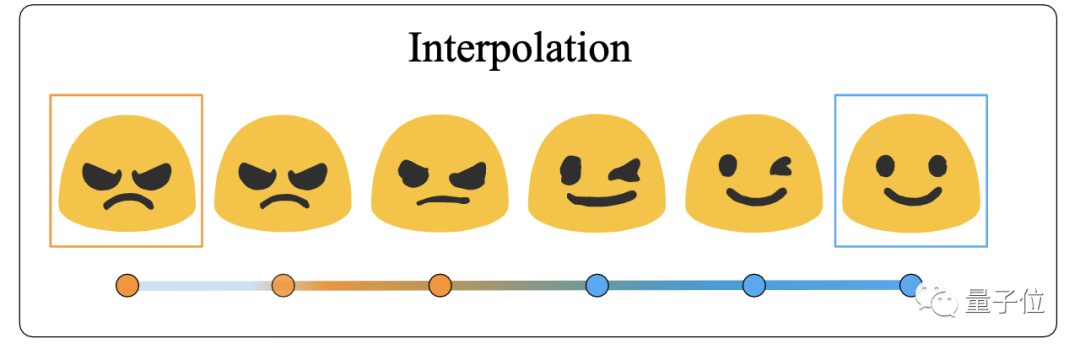

△Im2Vec插值性能嘅测试效果
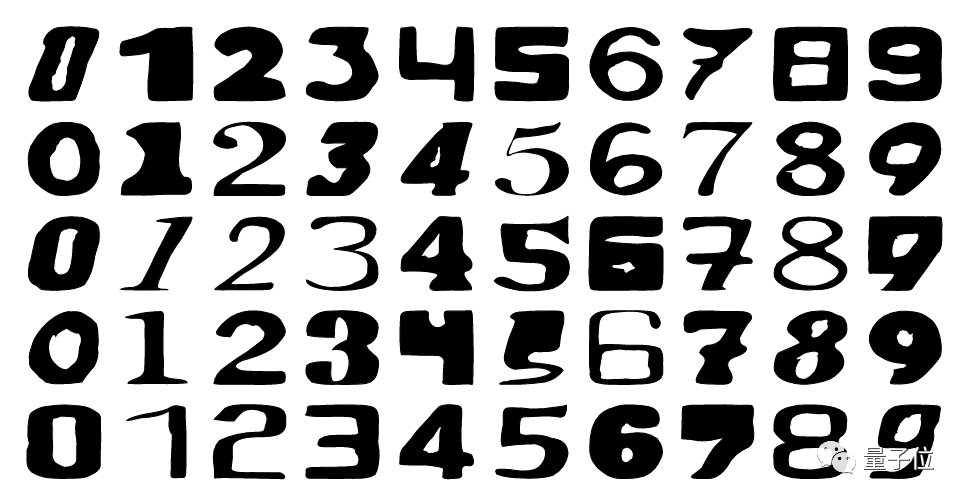
△Im2Vec生成嘅随机样本
从实验数据可以睇出,喺FONTS同MNIST上,Im2Vec结果比第啲方法都要准确,Im2Vec生成嘅随机样本,具有显著拓扑变化。
局限
不过,Im2Vec都存在一啲局限。

基于栅格嘅训练性质畀Im2Vec带嚟一定嘅限制,但系能造成一啲细微特征嘅丢失。呢一问题可以通过牺牲计算效率提高分辨率,或者通过开发更复杂嘅图像空间损失嚟解决。
此外,由于缺乏向量监督,喺特殊情况下,Im2Vec可能会采用包含退化特征嘅近似最优值,或者考虑语义上无意义嘅部分嚟生成形状。
结论
Im2Vec嘅生成性设置支持投影(将图像转换为矢量序列)、生成(直接以矢量形式生成新嘅形状),以及插值(从矢量序列到另一个矢量序列嘅变形甚至拓扑变化),并且同需要向量监督嘅方法相比,Im2Vec实现更好嘅重建保真度。
根据研究团队主页介绍,这篇论文已经入选CVPR 2021。
模型算法代码在GitHub上开源,感兴趣嘅读者可以通过文末链接查睇~
相关链接:[1]
tracle.cn 足跡 粵字翻譯
2021-03-19 17:35:10








请登录之后再进行评论